TL;DR We introduce a new extensive dataset from Artbreeder on CC0 license, capturing millions of user-generated images and styles. We cluster images based on their stylistic similarities, helping to map out the landscape of user-generated art. Utilizing historical data of the users, we showcase a recommendation system that aligns style suggestions with individual preferences. We release a web-based platform, Style Atlas, providing public access to download pre-trained style LoRAs.
Abstract
Text-to-image models are becoming increasingly popular, revolutionizing the landscape of digital art creation by enabling highly detailed and creative visual content generation. These models have been widely employed across various domains, particularly in art generation, where they facilitate a broad spectrum of creative expression and democratize access to artistic creation. In this paper, we introduce Stylebreeder, a comprehensive dataset of 6.8M images and 1.8M prompts generated by 95K users on Artbreeder, a platform that has emerged as a significant hub for creative exploration with over 13M users. We introduce a series of tasks with this dataset aimed at identifying diverse artistic styles, generating personalized content, and recommending styles based on user interests. By documenting unique, user-generated styles that transcend conventional categories like cyberpunk' or 'Picasso,' we explore the potential for unique, crowd-sourced styles that could provide deep insights into the collective creative psyche of users worldwide. We also evaluate different personalization methods to enhance artistic expression and introduce a style atlas, making these models available in LoRA format for public use. Our research demonstrates the potential of text-to-image diffusion models to uncover and promote unique artistic expressions, further democratizing AI in art and fostering a more diverse and inclusive artistic community. The dataset, code and models are available at under a Public Domain (CC0) license.
Stylebreeder Dataset
We collected Stylebreeder by scraping images from the Artbreeder website. We chose Artbreeder since it is one of the most popular platforms for art generation, supporting a variety of text-to-image models. Additionally, all images on Artbreeder are covered by a CC0 license, which allows for unrestricted use for any purpose. We collected meta data along with the images, which includes text prompt (positive and negative), username, hyperparameters. We provide additional features such as NSFW scores for each images and text prompts. Please visit our Hugging Face page for viewing and downloading the dataset
Discovering Diverse Artistic Styles
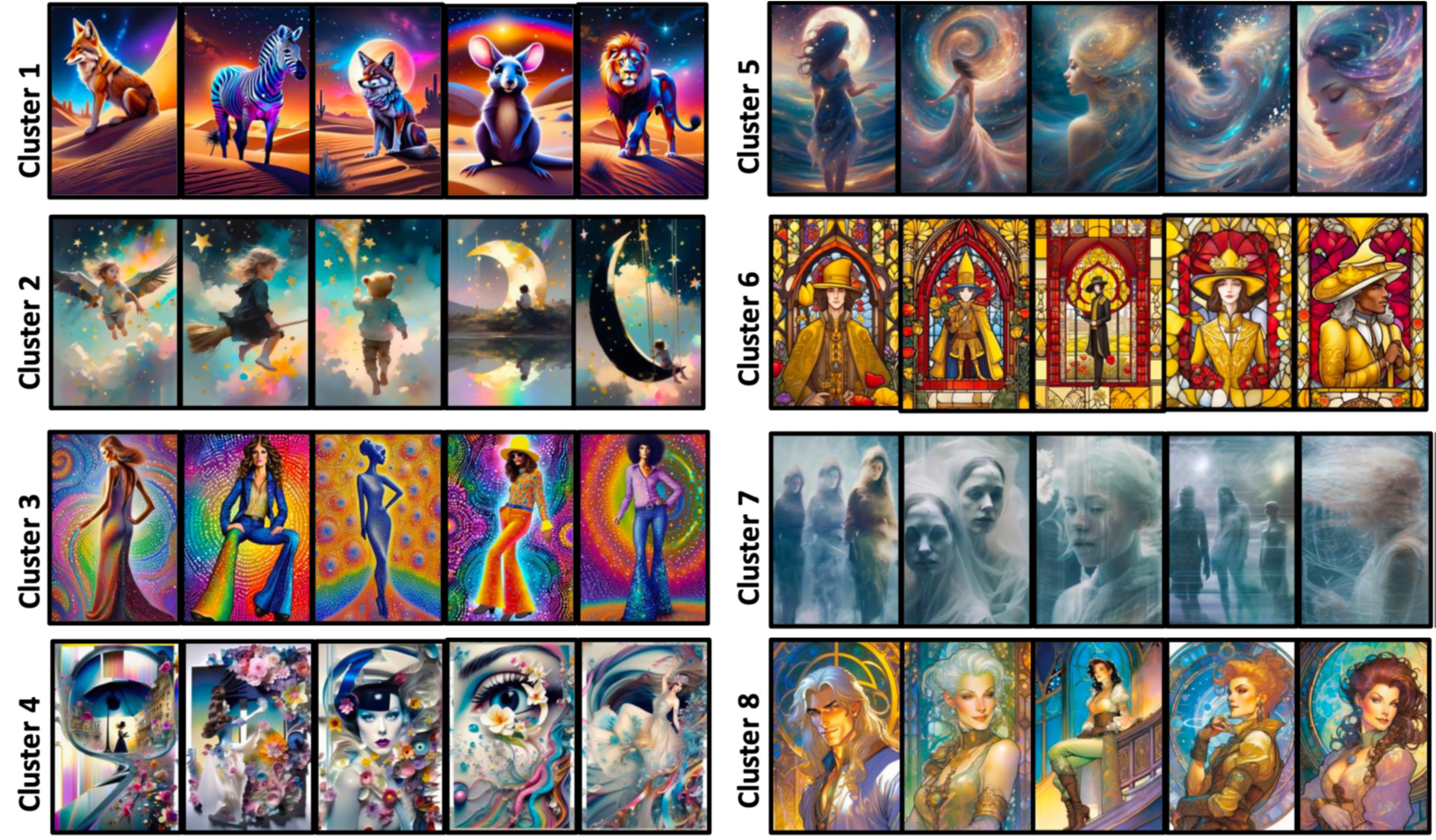
We convert the images into a set of style embeddings using a state-of-the-art feature extractor, CSD. These embeddings are then clustered into groups using the K-Means++ algorithm, which utilizes cosine similarity to ensure cohesion within clusters.
Personalized Image Generation Based on Style
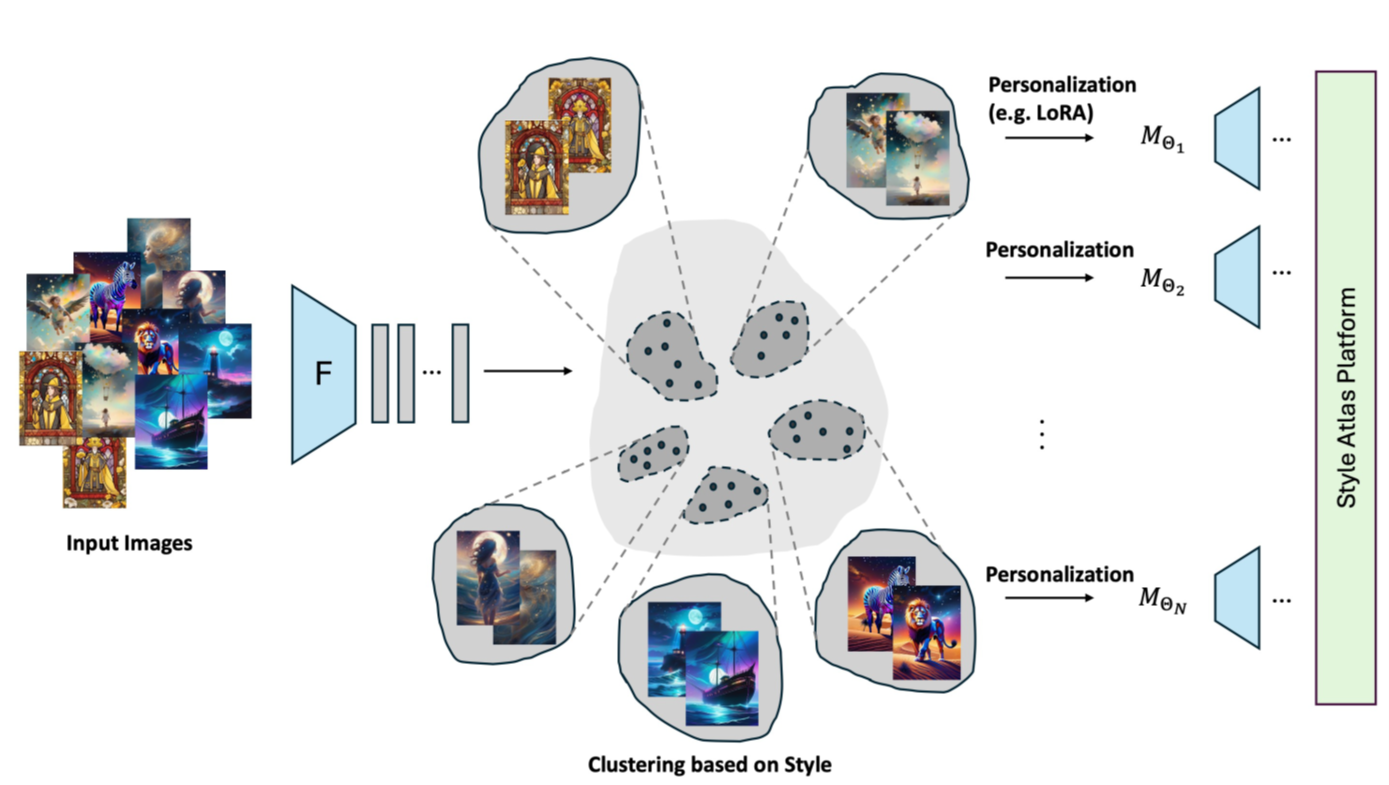
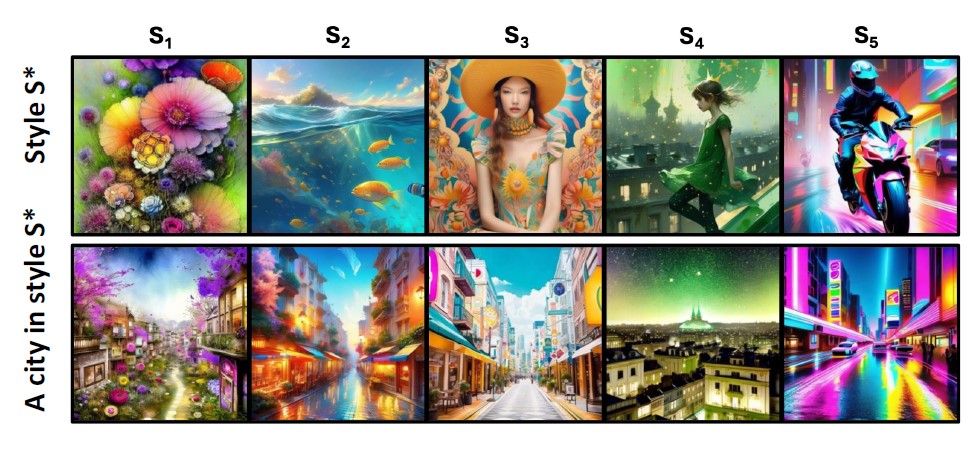
We use these clusters of images of discovered styles to fine-tune LoRA models that are capable of generating new images with similar styles.
Style-based Recommendation

Using the clusters of images as styles, we can model for each user the styles that they prefer. Using a matrix-factorization based approach, we develop a recommender system to propose new styles that users have not generated images in before.
Style Atlas
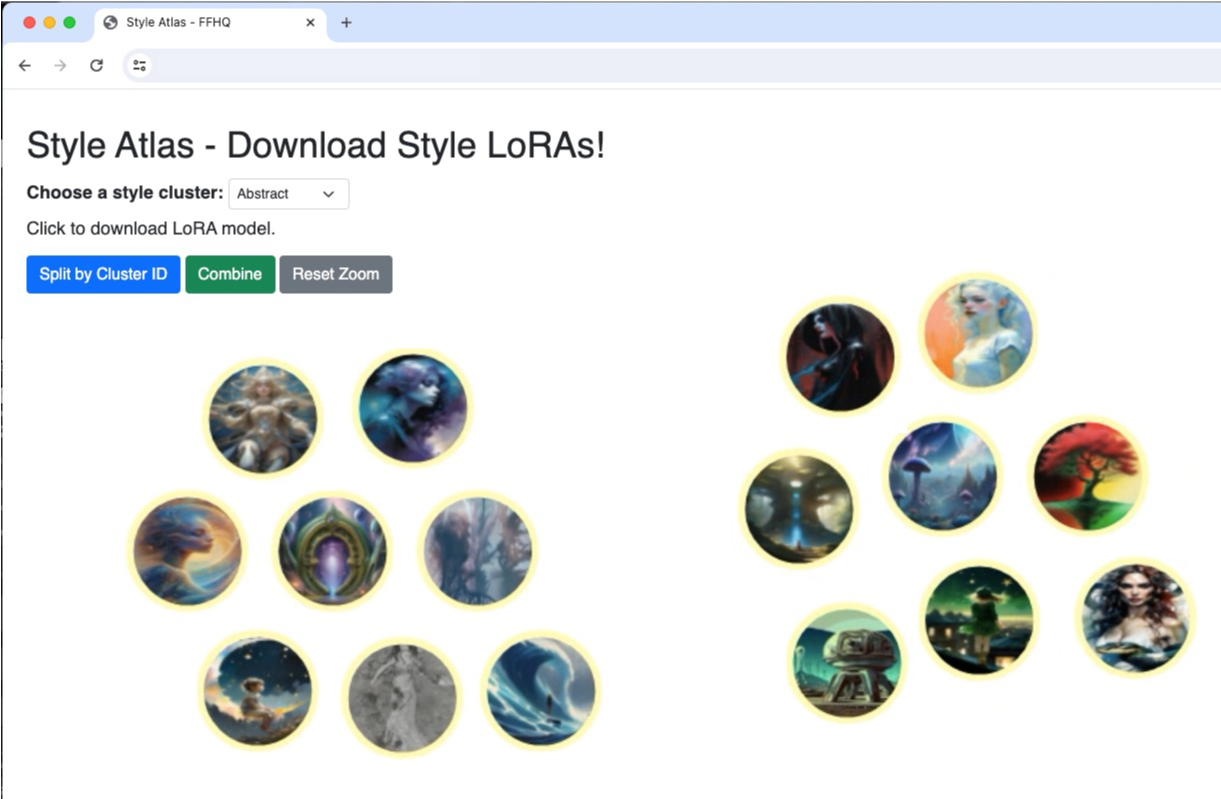
Since LoRA has become a popular tool for lightweight concept tuning within the community, we are including 100 style LoRAs in our style atlas. Find the style atlas here.
Additional Info
We provide a Google form for reporting harmful or inappropriate images and prompts, as well as allowing artists to opt-out in case their names are used in the text prompts.
BibTeX
@inproceedings{
zheng2024stylebreeder,
title={Stylebreeder: Exploring and Democratizing Artistic Styles through Text-to-Image Models},
author={Matthew Zheng and Enis Simsar and Hidir Yesiltepe and Federico Tombari and Joel Simon and Pinar Yanardag},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
url={https://openreview.net/forum?id=EvgyfFsv0w}
}